
Fixing the issue in assumption of OLS step by step or one by one
Posted by: admin 2 months ago
Hi, I want to raise the issue related to know whether your OLS is ok or not.
Linear
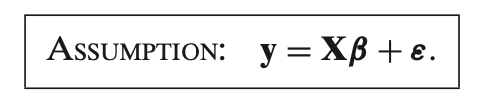
This assumption is the **linear regression model** equation, which states that the **observed values** of the dependent variable
Breaking it down:
1. **
2. **
-
-
Together,
3. **
### In Simple Terms
This assumption states that:
- The relationship between the predictors (independent variables) and the outcome (dependent variable) is **linear**.
- The outcome
This is a core assumption in **linear regression** models and forms the basis for estimating the coefficients
Fullrank
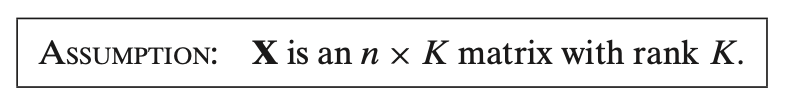
This assumption states that **
1. **
- **
- **
- So,
2. **Rank
- The **rank** of a matrix is the number of linearly independent columns. In this case, having **rank
- **Linear independence** means that no column in
- This assumption is crucial for estimating the coefficients
### Why This Assumption is Important
- **Ensures Uniqueness of Coefficients**: With full rank
- **Avoids Multicollinearity**: If the rank of
### In Simple Terms
This assumption requires that the predictors in
Exogeneity
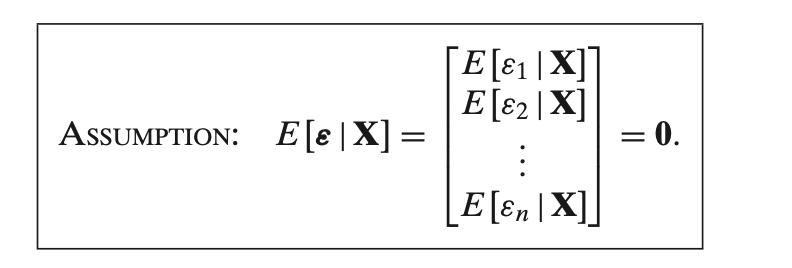
This assumption states that the **expected value of the error term
### What This Means
1. **Zero Conditional Mean Assumption**:
- This assumption implies that the errors
- For each observation
2. **Implication for Unbiasedness**:
- This assumption is crucial for the **unbiasedness** of the Ordinary Least Squares (OLS) estimator. If
- In other words, this assumption implies that **the predictors capture all relevant information** about the outcome variable, and any remaining error is random and unrelated to the predictors.
### In Simple Terms
This assumption states that the error term has **no systematic relationship with the predictors**. It ensures that the predictors
Yes, the assumption
- **Endogeneity** occurs when there is a correlation between the predictors (independent variables)
- **Exogeneity**, by contrast, means that the predictors are not correlated with the error term. This is precisely what the assumption
If this assumption does **not** hold (i.e., if
1. **Omitted Variable Bias**: If an important variable that affects both
2. **Simultaneity**: If there is a two-way causal relationship between
3. **Measurement Error**: If there are errors in measuring
### Why Endogeneity is Problematic
When endogeneity is present, the **OLS estimates** of the coefficients are **biased and inconsistent**. This means the estimated coefficients do not reflect the true relationship between
### Addressing Endogeneity
To deal with endogeneity, econometricians often use techniques such as:
- **Instrumental Variables (IV)**: Introducing variables that are correlated with
- **Fixed Effects Models**: In panel data, fixed effects can control for omitted variables that are constant over time.
- **Control Variables**: Including additional relevant variables that may be causing endogeneity due to omitted variable bias.
In summary, the assumption
Homokedasticy
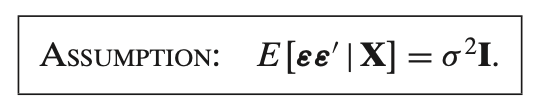
This assumption states that the **variance-covariance matrix** of the error term
1. **Variance-Covariance Matrix of Errors**:
-
- This matrix contains the variances of the errors on the diagonal and the covariances between different error terms on the off-diagonal.
2. **Assumption of Homoskedasticity**:
- The expression
- **Homoskedasticity** means that the variance of the error term is the same across all values of
3. **No Correlation Between Errors (Independence)**:
- The identity matrix
- In other words, there is **no covariance** between the errors for different observations, meaning that each error term is independent of the others.
### Why This Assumption Matters
This assumption is crucial in **ordinary least squares (OLS) regression** because:
- It ensures that the **OLS estimators are efficient** (have the lowest variance among linear unbiased estimators) under the Gauss-Markov theorem.
- If this assumption does not hold (i.e., if there is heteroskedasticity or autocorrelation), the standard errors of the estimated coefficients might be incorrect, leading to unreliable statistical inference (such as incorrect confidence intervals and hypothesis tests).
### In Simple Terms
This assumption means that:
- **Each error term has the same variance** (no heteroskedasticity).
- **Error terms are independent** of each other (no autocorrelation).
In practical terms, it implies that the errors are spread out evenly and independently across observations, which helps ensure reliable OLS estimates. If this assumption is violated, adjustments such as **robust standard errors** or **generalized least squares (GLS)** may be used to obtain valid inference.
What is matrix identity
A **matrix identity** (often called the **identity matrix**) is a **square matrix** with ones on the **main diagonal** (from the top left to the bottom right) and zeros in all other positions. It serves as the equivalent of the number "1" in matrix operations, meaning that multiplying any matrix by the identity matrix leaves the original matrix unchanged.
### Properties of the Identity Matrix
1. **Notation and Structure**:
- The identity matrix is usually denoted by
- For an
- A 2x2 identity matrix looks like this:
- A 3x3 identity matrix looks like this:
2. **Multiplicative Identity**:
- The identity matrix behaves similarly to the number "1" in regular multiplication. For any matrix
- This property is fundamental in linear algebra and matrix operations, as it means that the identity matrix does not alter other matrices when used in multiplication.
3. **Role in Inverses**:
- The identity matrix is also important in defining **matrix inverses**. For a matrix
then
4. **Diagonal Structure**:
- The identity matrix has **1s on its main diagonal** and **0s elsewhere**. This structure makes it a diagonal matrix and a special case of the more general class of matrices called **diagonal matrices**.
### Summary
The identity matrix is a square matrix that acts as a neutral element in matrix multiplication, leaving other matrices unchanged when multiplied by them. It plays a fundamental role in linear algebra, especially in matrix operations involving multiplication, inverses, and transformations.
Normality
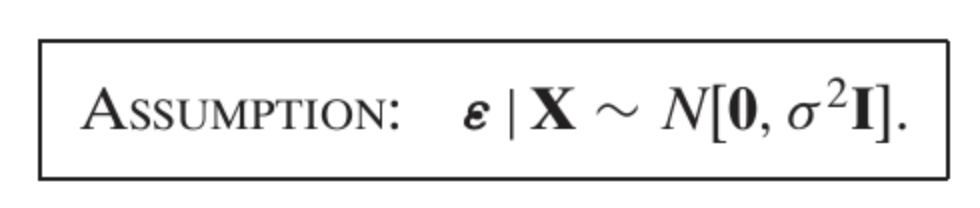
This assumption specifies that the **error term**
Breaking down the notation:
1. **
2. **
- **Mean 0**: The expected value of
- **Variance
### In Simple Terms
This assumption means:
- **Errors are normally distributed** around zero.
- **Errors have constant variance**
- **Errors are independent** of each other (no correlation).
This assumption is commonly used in **ordinary least squares (OLS) regression** and other linear models to simplify estimation and inference, as it ensures that estimators are **unbiased and efficient** under the classical linear regression model.







0 Comments